With the release of KEDA version 1, it is a good time to have a quick look at what it is and what it does!
In this post I will investigate the basics of KEDA using a Kafka trigger and look at what the properties mean and how it affects the scaling of your pods.
All the sample code used in this post is also available in this GitHub repository.
KEDA
So what actually is KEDA? KEDA (Kubernetes-based Event Driven Autoscaler) is an MIT licensed open source project from Microsoft and Red Hat that aims to provide better scaling options for your event-driven architectures on Kubernetes.
Let’s have a look at what this means.
Currently on Kubernetes, the HPA (Horizontal Pod Autoscaler) only reacts to resource-based metrics such as CPU or memory usage or custom metrics. From my understanding, for event-driven applications where there could suddenly be a stream of data, this could be quite slow to scale up. Never mind scaling back down once the data stream is lessening and removing the extra pods.
I imagine paying for those unneeded resources all the time wouldn’t be too fun!
KEDA is more proactive. It monitors your event source and feeds this data back to the HPA resource. This way, KEDA can scale any container based on the number of events that need to be processed, before the CPU or memory usage goes up. You can also explicitly set which deployments KEDA should scale for you. So, you can tell it to only scale a specific application, e.g. the consumer.
As KEDA can be added to your existing cluster, it is quite flexible on how you want to use it. You don’t need to do a code change and you don’t need to change your other containers. It only needs to be able to look at your event source and the deployment(s) you are interested in scaling.
That felt like a lot of words! Let’s have a look at this diagram for a high-level view of what KEDA does.
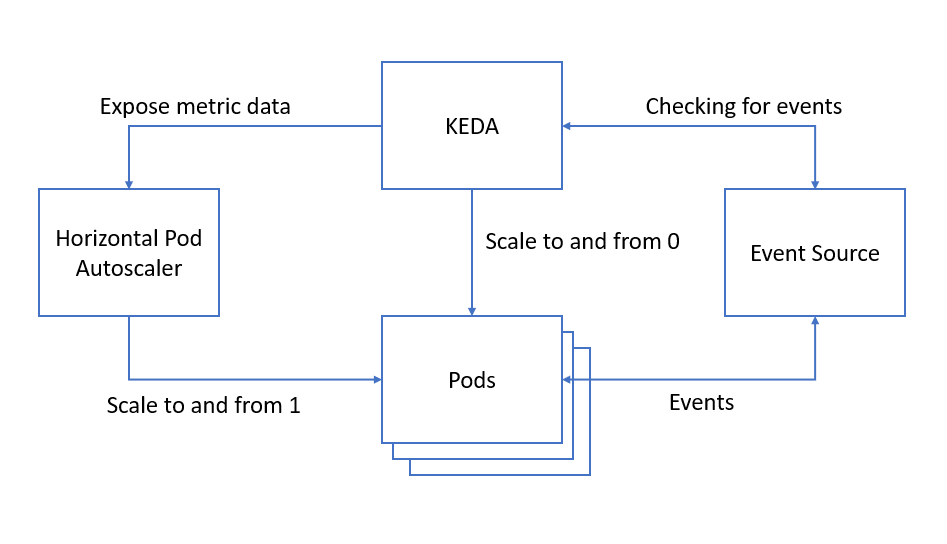
KEDA monitors your event source and regularly checks if there are any events. When needed, KEDA will then activate or deactivate your pod depending on whether there are any events by setting the deployment’s replica count to 1 or 0, depending on your minimum replica count. KEDA also exposes metric data to the HPA which handles the scaling to and from 1.
This sounds straightforward to me! Let’s have a closer look at KEDA now.
Deploying KEDA
The instructions for deploying KEDA are very simple and can be found on KEDA’s deploy page .
There are two ways to deploy KEDA into your Kubernetes cluster:
- Helm
- Deploy yaml
So what gets deployed? The deployment contains the KEDA operator, roles and role bindings and these custom resources:
-
ScaledObject
The ScaledObject maps an event source to the deployment that you want to scale.
-
TriggerAuthentication
If required, this resource contains the authentication configuration needed for monitoring the event source.
The scaled object controller also creates the HPA for you.
ScaledObject Properties
Let’s take a closer look at the ScaledObject.
This is a code snippet of the one I used in my sample repository.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
apiVersion: keda.k8s.io/v1alpha1
kind: ScaledObject
metadata:
name: consumer-scaler
labels:
deploymentName: consumer-service
spec:
scaleTargetRef:
deploymentName: consumer-service
pollingInterval: 1
cooldownPeriod: 60
minReplicaCount: 0
maxReplicaCount: 10
triggers:
- type: kafka
metadata:
topic: messages
brokerList: kafka-cluster-kafka-bootstrap.keda-sample:9092
consumerGroup: testSample
lagThreshold: '3'
The ScaledObject and the deployment referenced in deploymentName need to be
in the same namespace.
So let’s look at each property in the spec section and see what they are used for.
scaleTargetRef:
deploymentName: consumer-service
This is the reference to the deployment that you want to scale. In this example, I have a consumer-service app that I want to scale depending on the number of events coming through to Kafka.
pollingInterval: 1 # Default is 30
The polling interval is in seconds. This is the interval in which KEDA checks the triggers for the queue length or the stream lag.
cooldownPeriod: 60 # Default is 300
The cooldown period is also in seconds and it is the period of time to wait after the last trigger activated before scaling back down to 0.
But what does activated mean and when is this? Having a look at the code and the documentation, activated is the time at which KEDA last checked the event source and found that there were events, this sets the trigger to active.
The next time KEDA looks at the event source and finds it empty, then the trigger is set to inactive and then kicks off the cool down period before scaling down to 0.
This timer is cancelled if any events are detected again in the event source.
This could be interesting to balance with the polling interval to make sure it doesn’t scale down too fast before the events are done being consumed!
minReplicaCount: 0 # Default is 0
This is the minimum number of replicas that KEDA will scale a deployment down to.
maxReplicaCount: 10 # Default is 100
This is the maximum number of replicas that KEDA will scale up to.
triggers:
- type: kafka
This is the list of triggers to use to activate the scaling. In this example, I use Kafka as my event source.
Kafka Trigger
Although KEDA supports multiple types of event source, we will be looking at using the Kafka scaler in this post.
1
2
3
4
5
6
7
triggers:
- type: kafka
metadata:
topic: messages
brokerList: kafka-cluster-kafka-bootstrap.keda-sample:9092
consumerGroup: testSample
lagThreshold: '3'
Kafka Trigger Properties
topic: messages
This is the name of the topic that you want to check the events in.
brokerList: kafka-cluster-kafka-bootstrap.keda-sample:9092
Here you can list the brokers that KEDA should monitor on as a comma separated list.
consumerGroup: testSample
This is the name of the consumer group and should be the same one as the one that is consuming the events from the topic so that KEDA knows which offsets to look at.
lagThreshold: '3' # Default is 10
This one actually took me a while to figure out, but that is probably down to my inexperience in this area!
In the documentation, this is described as how much the event stream is lagging. So, I thought it was something with time.
In reality, the lag refers to the number of records that haven’t been read yet by the consumer.
KEDA checks against the total number of records in each of the partitions and the last consumed record. After some calculations, this is used to identify how much it should scale the deployments.
For Kafka, the number of partitions in your topic affects how KEDA handles the scaling as it will not scale beyond the number of partitions you requested for your topic.
Example
So, what does this look like in practice? In the sample repository you can find a very simple consumer service using Kafka as the event source. We will be using this to experiment with KEDA.
The repository contains the Kafka and Zookeeper servers, a basic consumer service that simply outputs the messages from the Kafka topic and our KEDA scaler.
If you want to try along as you read, you can find the instructions to start up the services in the README.
Let’s start!
Here is how the keda-sample namespace looks like before KEDA is started:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
$ kubectl get all -n keda-sample
NAME READY STATUS RESTARTS AGE
pod/consumer-service-5887df99d7-hgcnc 1/1 Running 0 15s
pod/kafka-cluster-entity-operator-784dbf5d5f-nkqz2 3/3 Running 0 29s
pod/kafka-cluster-kafka-0 2/2 Running 0 54s
pod/kafka-cluster-zookeeper-0 2/2 Running 0 78s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/consumer-service ClusterIP 10.98.226.160 <none> 8090/TCP 15s
service/kafka-cluster-kafka-0 NodePort 10.104.101.0 <none> 9094:32000/TCP 54s
service/kafka-cluster-kafka-bootstrap ClusterIP 10.106.255.132 <none> 9091/TCP,9092/TCP,9093/TCP 54s
service/kafka-cluster-kafka-brokers ClusterIP None <none> 9091/TCP,9092/TCP,9093/TCP 54s
service/kafka-cluster-kafka-external-bootstrap NodePort 10.97.47.72 <none> 9094:32100/TCP 54s
service/kafka-cluster-zookeeper-client ClusterIP 10.100.96.220 <none> 2181/TCP 78s
service/kafka-cluster-zookeeper-nodes ClusterIP None <none> 2181/TCP,2888/TCP,3888/TCP 78s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/consumer-service 1/1 1 1 15s
deployment.apps/kafka-cluster-entity-operator 1/1 1 1 29s
NAME DESIRED CURRENT READY AGE
replicaset.apps/consumer-service-5887df99d7 1 1 1 15s
replicaset.apps/kafka-cluster-entity-operator-784dbf5d5f 1 1 1 29s
NAME READY AGE
statefulset.apps/kafka-cluster-kafka 1/1 54s
statefulset.apps/kafka-cluster-zookeeper 1/1 78s
You can see that there is one pod for the consumer-service currently active.
So, what happens after you start up the KEDA scaler?
1
2
3
4
5
6
7
8
$ kubectl get all -n keda-sample
NAME READY STATUS RESTARTS AGE
pod/kafka-cluster-entity-operator-784dbf5d5f-nkqz2 3/3 Running 0 12m
pod/kafka-cluster-kafka-0 2/2 Running 0 13m
pod/kafka-cluster-zookeeper-0 2/2 Running 0 13m
...
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
horizontalpodautoscaler.autoscaling/keda-hpa-consumer-service Deployment/consumer-service <unknown>/3 (avg) 1 10 0 10s
You can see that the HPA is created and the consumer-service pod disappeared.
Let’s try and send a message to the Kafka topic.
1
2
$ ./kafka-console-producer.bat --broker-list localhost:32100 --topic messages
>Hello World
1
2
3
4
5
6
$ kubectl get all -n keda-sample
NAME READY STATUS RESTARTS AGE
pod/consumer-service-5887df99d7-4g6jk 1/1 Running 0 68s
...
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
horizontalpodautoscaler.autoscaling/keda-hpa-consumer-service Deployment/consumer-service 0/3 (avg) 1 10 1 149m
A new consumer-service pod is back up! Once the cooldown period has passed, we can see that the pod is removed again as there were no more events in the topic.
1
2
3
4
5
6
7
8
$ kubectl get all -n keda-sample
NAME READY STATUS RESTARTS AGE
pod/kafka-cluster-entity-operator-784dbf5d5f-nkqz2 3/3 Running 0 162m
pod/kafka-cluster-kafka-0 2/2 Running 0 162m
pod/kafka-cluster-zookeeper-0 2/2 Running 0 163m
...
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
horizontalpodautoscaler.autoscaling/keda-hpa-consumer-service Deployment/consumer-service <unknown>/3 (avg) 1 10 0 149m
What happens if I send many messages at once to Kafka? Let’s see!
1
2
3
4
5
6
7
8
9
10
$ kubectl get all -n keda-sample
NAME READY STATUS RESTARTS AGE
pod/consumer-service-5887df99d7-54gqf 1/1 Running 0 17s
pod/consumer-service-5887df99d7-7gv8m 1/1 Running 0 39s
pod/consumer-service-5887df99d7-d5tg5 1/1 Running 0 33s
pod/consumer-service-5887df99d7-kzrm5 1/1 Running 0 33s
pod/consumer-service-5887df99d7-t4fnm 1/1 Running 0 33s
...
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
horizontalpodautoscaler.autoscaling/keda-hpa-consumer-service Deployment/consumer-service 0/3 (avg) 1 10 5 3h3m
There are 5 pods up! It won’t create more than that as I only have 5 partitions set in my Kafka topic.
So, I see what happens when I manually send messages here and there, but what happens in a more real situation when there is a stream of messages?
1
./kafka-producer-perf-test.bat --topic messages --throughput 3 --num-records 1000 --record-size 4 --producer-props bootstrap.servers=localhost:32100
This command will send 1000 messages to the topic, throttled at 3 per second.
1
2
3
4
5
6
7
8
$ kubectl get all -n keda-sample
NAME READY STATUS RESTARTS AGE
pod/consumer-service-5887df99d7-nvqkn 0/1 ContainerCreating 0 2s
pod/consumer-service-5887df99d7-wwgqp 1/1 Running 0 2m4s
pod/consumer-service-5887df99d7-zk5l9 1/1 Running 0 2m5s
...
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
horizontalpodautoscaler.autoscaling/keda-hpa-consumer-service Deployment/consumer-service 4/3 (avg) 1 10 2 4h37m
You can see more pods getting created over time to help handle the events that are coming in.
1
2
3
4
5
6
7
8
9
10
$ kubectl get all -n keda-sample
NAME READY STATUS RESTARTS AGE
pod/consumer-service-5887df99d7-5q59s 1/1 Running 0 3m48s
pod/consumer-service-5887df99d7-nvqkn 1/1 Running 0 4m3s
pod/consumer-service-5887df99d7-vqtbg 1/1 Running 0 3m48s
pod/consumer-service-5887df99d7-wwgqp 1/1 Running 0 6m5s
pod/consumer-service-5887df99d7-zk5l9 1/1 Running 0 6m6s
...
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
horizontalpodautoscaler.autoscaling/keda-hpa-consumer-service Deployment/consumer-service 0/3 (avg) 1 10 5 4h41m
And once no more events are found in the topic, the deployments get scaled back down.
1
2
3
4
5
6
7
8
9
10
$ kubectl get all -n keda-sample
NAME READY STATUS RESTARTS AGE
pod/consumer-service-5887df99d7-5q59s 0/1 Terminating 0 4m18s
pod/consumer-service-5887df99d7-nvqkn 0/1 Terminating 0 4m33s
pod/consumer-service-5887df99d7-vqtbg 0/1 Terminating 0 4m18s
pod/consumer-service-5887df99d7-wwgqp 0/1 Terminating 0 6m35s
pod/consumer-service-5887df99d7-zk5l9 1/1 Terminating 0 6m36s
...
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
horizontalpodautoscaler.autoscaling/keda-hpa-consumer-service Deployment/consumer-service 0/3 (avg) 1 10 5 4h41m
Jobs
KEDA doesn’t just scale deployments, but it can also scale your Kubernetes jobs.
Although I haven’t tried this out, it sounds quite interesting! Instead of having many events processed in your deployment and scaling up and down based on the number of messages needing to be consumed, KEDA can spin up a job for each message in the event source.
Once a job completes processing its single message, it will terminate.
You can configure how many parallel jobs should be run at a time as well, similar to the maximum number of replicas you want in a deployment.
KEDA offers this as a solution to handling long running executions as the job only terminates once the message processing has completed as opposed to deployments which terminate based on a timer.